Incident Response Training for Junior Engineers: A 4-Stage Programme

Ready to make incident response your competitive advantage?
See how Uptime Labs builds provable, scalable incident response capability across your financial services organisation.
Incident response training for junior engineers works in four stages: structured knowledge transfer (post-mortems, runbooks, architecture docs), formal shadow rotations, safe simulation practice in a realistic environment, and objective readiness criteria before going on-call independently.
Most teams onboard junior engineers the same way: point them at the runbooks, pair them with a senior for a few weeks (shadowing), then add them to the rotation and hope for the best. That approach transfers information. It does not build the judgment, communication instincts, or tool familiarity that incident response actually requires.
This guide covers a repeatable four-stage programme that gets junior engineers genuinely ready for independent on-call, with clear criteria for knowing when they can carry the pager alone.
Why Incident Response Training for Junior Engineers Is an Organisational Problem
Junior engineer on-call readiness is a structural reliability problem, not a talent problem. When engineers go on-call without adequate preparation, the consequences land on the entire team: longer MTTR, more escalations to senior engineers, and the slow accumulation of on-call stress that drives burnout, and talent churn.
Reducing the stress related to being on-call matters because the importance of services and the consequences of potential outages create significant pressure on on-call engineers, damaging the well-being of individual team members and possibly prompting incorrect choices that endanger service availability.
The problem compounds at the team level. If one engineer is carrying a disproportionate share of incidents because they built the system or they are the most senior, that is a knowledge distribution problem. Junior engineers who are not ready for on-call do not just struggle themselves; they pull senior engineers back into incidents that a prepared junior could have handled.
The trial by fire method of orienting new engineers is often born out of a reactive team environment. If you are lucky, the engineers who are already good at navigating ambiguity will crawl out of the hole you have put them in. But chances are, this strategy has alienated several capable engineers.
A structured training programme fixes this. The four stages below are sequential by design. Each one builds on the last.
Stage 1: Building Foundational Knowledge Before On-Call
Knowledge transfer is the foundation of on-call readiness. A junior engineer cannot diagnose what they do not understand. This stage is about building a mental model of the systems they will be responsible for before any incident pressure exists.
Start with Post-Mortems, Not Documentation
Post-mortems are the richest learning resource on any SRE team. They show real failure modes, real decision timelines, and real gaps in process. A junior engineer who has read 10 post-mortems for the services they will own understands failure patterns that no architecture diagram can convey.
Assign post-mortems in order of relevance to the services the junior engineer will cover. Ask them to write a one-paragraph summary of each one: what failed, why it was not caught sooner, and what the fix was. This forces active reading rather than passive scanning.
Runbooks as Active Learning, Not Reference Material
Runbooks dramatically reduce MTTR, lower the cognitive load on on-call engineers, and reduce the fear that makes burnout worse. They are especially valuable for junior engineers or anyone onboarded into a complex system quickly.
The mistake most teams make is treating runbooks as something to read once and file away. Instead, ask junior engineers to walk through each runbook step-by-step in a non-production environment, verifying that every command works and every link resolves. As playbooks can become obsolete with each new deployment, the on-call engineer is responsible for keeping them updated. This task gives junior engineers ownership of documentation quality from day one, which accelerates both learning and trust-building with senior colleagues.
Architecture Walkthroughs and Dependency Mapping
Junior engineers need to understand not just what their services do, but how they connect to everything else. A live walkthrough with a senior engineer is essential here. Questions asked in the room surface gaps that documentation alone never would.
Run a structured architecture walkthrough covering:
- Service dependencies and upstream/downstream failure blast radius
- Key SLIs and what triggers a page
- Escalation paths: who owns what, and when to call them
- The toolchain they will use during an incident (dashboards, log aggregators, alerting platforms)
Understanding blast radius at this stage matters because it directly informs how the engineer will triage in simulation and on-call. When a junior engineer encounters a cascading failure in Stage 3, their ability to scope the impact depends on the mental model they build here.
They don’t need to understand everything about a system: that’s unrealistic. What they do need to have is a basic understanding of each layer of the system’s architecture. A strong onboarding will ensure this.
Stage 2: Shadow Rotations for On-Call Readiness
Shadow rotations are a formal, scheduled step in on-call readiness, not an informal mentorship arrangement. A shadow rotation is a dedicated schedule layer where a junior engineer is paired with an experienced primary responder for a defined period, with clear expectations on both sides and structured debriefs after every incident.
Before any engineer carries the pager independently, they should shadow an experienced colleague through real incidents. Shadow rotations build confidence, surface knowledge gaps early, and reduce the time it takes for new team members to contribute to incident response rather than just observe it.
How Google Structures the Shadow Phase
Once new SREs understand more about their systems and have done some hands-on work, they are ready to shadow on-call and begin updating incomplete or out-of-date documentation.
New engineers shadow more experienced, local SREs before joining the rotation. Good documentation and structured strategies help the team form a solid foundation and ramp up quickly. Although on-call can be stressful, the teams' confidence grows enough to take action without second-guessing themselves. There is psychological safety in knowing that their responses are based on the team's collective knowledge, and that even when they escalate, the on-call engineers are still regarded as competent engineers.
That psychological safety point is not a soft benefit. It directly affects decision quality. Engineers who have rehearsed the environment before carrying the pager make better decisions under pressure, because stress impairs the deliberate cognitive reasoning that incident diagnosis requires. Shadow rotations are where that rehearsal happens.
What the Shadow Engineer Should Actually Do
Passive observation is not enough. During a shadow rotation, the junior engineer should:
- Follow along in all incident channels in real time, not as a spectator but as an active note-taker
- Write their own diagnosis hypothesis before the senior engineer announces theirs
- Debrief after every incident: what did they get right, what did they miss, and why
- Take the lead on lower-severity incidents with the senior engineer available to intervene
During the shadowing process, the new SRE sits alongside the primary on-call engineer to learn about the on-call process in practice. As SREs progress in learning, they should be given more responsibilities until they can perform on-call duties independently.
A shadow rotation that produces no active outputs is a missed opportunity. Teams that need a structured framework for when and how to escalate should establish that before the shadow rotation begins, not during it. See UptimeLabs' guide to building an incident escalation process for a starting point.
Stage 3: Incident Response Simulation Practice (Building Muscle Memory Without Production Risk)
Shadow rotations expose junior engineers to real incidents. They do not give junior engineers the chance to make mistakes safely, try different diagnostic approaches, or practice the communication skills that incident response demands. Most organisations rely on static documentation or one-off tabletop exercises to develop these skills, but neither builds the muscle memory that separates a smooth, coordinated response from a disorganised scramble.
Simulation fills the gap between shadow rotations and independent on-call. It gives junior engineers a space to fail, learn, and repeat, without any production risk.
What Good Incident Response Simulation Practice Looks Like
The most common mistake with simulation is treating it as a one-time event. A single drill does not build muscle memory. A progressive series of drills, increasing in complexity over weeks, is the most effective way to build critical incident response instincts.
A minimum of 6 drills across these tiers is the threshold at which performance data becomes reliable. Teams with access to a larger drill library should continue beyond that with the scenarios becoming more valuable as complexity increases.
This mirrors the approach UptimeLabs uses across its drill library, where scenarios progress from environment introduction through to complex infrastructure debugging, and every drill tracks performance across 40+ skills including time to acknowledge, diagnostic accuracy, and communication clarity.
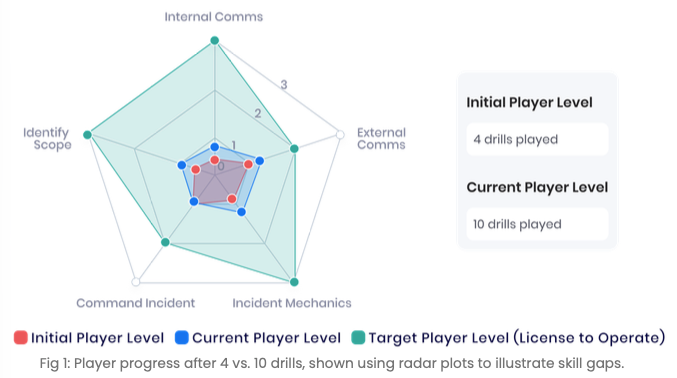
Why Simulation Produces Objective Readiness Data
The other advantage of structured simulation is that it produces measurable data and evidence of proficiency. After four drills, a junior engineer's performance profile starts to take shape. After ten drills, you have a radar chart showing proficiency across communication, diagnosis, escalation judgment, and tool use.
Proficiency levels typically range from Practitioner - indicating the engineer can handle incidents independently at a baseline level - through to Expert. That data replaces the gut-feel answer to "is this engineer ready?" with an objective one.
UptimeLabs' platform acts as a ‘gym’ for on-call teams, generating realistic technical failures (latency spikes, database locks, cyber breaches) that teams must debug and resolve in a live, safe environment. Drill scenarios include AI-driven characters who replicate the unpredictable stakeholder pressure described above - not scripted prompts, but behavioural responses that reflect what the engineer is doing. Each session ends with scored feedback by skill category, giving junior engineers a clear picture of where they are strong and where they need more reps.
Stage 4: Objective On-Call Readiness Criteria (Knowing When They Are Ready)
The most common failure point in junior engineer on-call programmes is the readiness gate. Most teams rely on a senior engineer's subjective assessment: "I think they're ready." That assessment is influenced by how confident the junior engineer seems, how recent the last incident was, and how stretched the rotation is. None of those factors measure actual readiness.
Define readiness criteria in advance, before the junior engineer starts training. Make them specific and measurable.
Suggested On-Call Readiness Checklist for Junior Engineers
A junior engineer is ready to carry the pager independently when they can demonstrate:
- Knowledge transfer complete: Has reviewed all post-mortems for covered services in the last 12 months; can explain the top five failure modes without prompting
- Runbook familiarity: Has walked through every runbook step-by-step and submitted at least one update
- Shadow rotation complete: Has completed a minimum of two full on-call shifts as a shadow, with written debriefs for each incident observed
- Simulation performance: Has completed a minimum of 6 drills with proficiency scores at or above the team's defined Practitioner level across triage, communication, and escalation judgment. If completing a program like Uptime Labs’ Incident Essentials, they may be awarded a certificate upon successful completion.
- Stakeholder communication: Can write a clear, accurate incident update for a non-technical stakeholder within 5 minutes of a simulated page
- Escalation judgment: Has demonstrated correct escalation decisions (neither over-escalating nor holding too long) across at least 3 simulated scenarios
The typical best practice is to place junior engineers on the primary on-call rotation and schedule senior engineers as backup or secondary rotation. This helps junior engineers develop the required on-call skills while avoiding panic when there is an issue beyond their expertise.
The Primary/Secondary model is the right structural choice once a junior engineer meets the readiness criteria above. In the Primary/Secondary model, a first-line responder carries the initial page while a backup escalates automatically if the primary does not acknowledge within a defined window. It is the most common structure for mid-sized teams and the best model for bringing junior engineers onto rotation safely.
Metrics to Track After Junior Engineers Join the On-Call Rotation
Readiness does not end at the point of joining the rotation. Track these metrics for the first 90 days:
- MTTA (Mean Time to Acknowledge): Are they acknowledging pages promptly? High MTTA indicates alert fatigue or schedule coverage gaps. For a junior engineer, a rising MTTA in the first 30 days can signal confidence issues, not alerting problems.
- Escalation rate: How often are they escalating, and at what point in the incident? Escalating very early could indicate they are not applying the diagnostic skills from training. Escalating very late could mean they are not comfortable asking for help.
- Post-incident review quality: Are they writing postmortems or PIRs that identify root causes and produce follow-up items? The quality of a junior engineer's postmortems is one of the best indicators of how much they are actually learning from live incidents. A strong debrief identifies the root cause rather than restating the symptoms, distinguishes the trigger from the contributing factors, and produces follow-up items that are specific and actionable rather than vague commitments to "improve monitoring." A junior engineer whose debriefs are improving in specificity over their first 90 days is internalising the diagnostic reasoning the programme was designed to build.
The real measure of whether this programme is working is not just the junior engineer's individual metrics. It is whether the senior engineers' escalation load is decreasing. When juniors handle incidents independently, seniors stop absorbing the escalations that a prepared junior could have resolved. The on-call load distributes as intended - not just on the schedule, but in practice.
Consequently, if senior escalation volume has not dropped within 90 days of a junior engineer joining the rotation, the readiness criteria were either set too low or the training programme had gaps that live incidents are now exposing.
Common Mistakes in Incident Response Training for Junior Engineers
Using a single simulation drill as a readiness gate. One drill measures performance in one scenario. It does not measure consistency. A minimum of 6 drills across varying difficulty levels is the threshold at which performance data becomes reliable.
Setting readiness criteria after the training starts. Define the criteria before day one. Engineers train harder and more purposefully when they know exactly what ‘ready’ looks like.
Conflating confidence with competence. A junior engineer who seems confident after a shadow rotation may simply have not encountered a complex incident yet. A junior can shadow ten quiet shifts and still be unprepared for a Sev-1. Simulation exposes the gaps that shadow rotations miss, because the scenario can be designed to surface them.
Skipping post-incident reviews. Postmortems (or PIRs) are the learning mechanism of on-call programmes. When something goes wrong, the goal is to understand what happened and how to prevent recurrence, not to assign blame. For junior engineers, a debrief after every incident, including simulated ones, is what converts experience into retained learning. Skipping debriefs therefore breaks that learning loop.
This applies beyond the onboarding period. Practicing incident response with a regular cadence, even when no new engineer is joining the rotation, keeps the whole team's systems knowledge current. The teams that stop drilling once the junior is on the rotation are the same teams that find their MTTR creeping back up six months later.
How Uptime Labs Supports Incident Response Training for Junior Engineers
Uptime Labs is the platform that implements the simulation and readiness measurement stages of this programme. Junior engineers run through a progressive drill library in a browser-based environment that mirrors production, with real dashboards, comms channels, and stakeholder pressure built into every scenario.
After each drill, performance is scored across 40+ metrics and plotted on a radar chart. Heads of SRE get a clear view of where each junior engineer sits relative to the team's defined Practitioner threshold, and where additional practice may be needed before they carry the pager.
Try a drill to see the simulation environment directly, or book a demo to walk through how the programme maps to your team's on-call onboarding process.
FAQs: Incident Response Training for Junior Engineers
What is a shadow rotation in SRE on-call training?
A shadow rotation is a formal, scheduled period where a junior engineer observes and participates in real incidents alongside an experienced primary on-call engineer, before carrying the pager independently. It is distinct from informal mentorship: it has a defined start and end point and clear progression criteria. Shadow rotations are standard practice in high-performing SRE teams, including Google's.
Are simulations and shadow rotations interchangeable?
No. Shadow rotations and simulation serve different purposes and work best in sequence. Shadow rotations expose junior engineers to real incidents with real consequences, building context and situational awareness. Simulation gives them a space to make mistakes, try different approaches, and build muscle memory without production risk. Both stages are necessary. Simulation is most effective combined with shadow rotations, not instead of them.
How does Uptime Labs help with junior engineer incident response training?
Uptime Labs provides a browser-based simulation platform where junior engineers run through progressive incident drills in a realistic environment that mirrors production. Drills start with environment orientation and scale up to complex Kubernetes debugging and stakeholder pressure scenarios. Performance is tracked across 40+ skills with proficiency levels from Practitioner to Expert, giving engineering leaders objective data on when a junior engineer is ready for independent on-call.
Peter Catack (Community Contributor)




